
Pretty jazzed that my sister has joined the blogosphere and is posting a wealth of wisdom and health information for the world wide websters to ponder and enjoy.
Creating Cycle Time Charts from TFS
Unfortunately, TFS doesn’t have ready-made or easily accessible metrics charts like I’m used to with Jira. There is a lot of clicking and waiting, in my experience. Queries have to be created then assigned to widgets then added to dashboards. Worse, sometimes things I need just aren’t available. For example, there is no cycle time chart built into TFS. There is a plug-in available for preview for VSTS, but as of this posting that plugin won’t be available for TFS. With Jira, cycle time and other charts are available and easily accessible out of the box.
Sigh. Nonetheless, we go to work with the tools we have. And if need be, we build the tools we need. In this post, I’ll give a high level description for how to create Cycle Time charts from TFS data using Python. I’ll leave it as an exercise for the reader to learn the value of cycle time charts and how to best use them.
To make life a little easier, I leveraged the open source (MIT License) TFS API Python client from the Open DevOps Community. To make it work for generating Cycle Time charts, I suggested a change to the code for accessing revisions. This was added in a subsequent version. For the remainder of this post I’m going to assume the reader has made themselves familiar with how this library works and resolved any dependencies.
OK, then. Time to roll up our sleeves and get to work.
First, let’s import a few things.
import csv from requests_ntlm import HttpNtlmAuth from tfs import TFSAPI import numpy as np import matplotlib.pyplot as plt
With that, we’re ready to make a call to TFS’s REST API. Again, to make things simple, I create a query in TFS to return the story cards I wish to look at. There are two slices I’m interested in, the past three and the past eight sprints worth of data. In the next block, I call the three sprint query.
# Anything in angle brackets "<>" is a placeholder for actual values.
# I keep the values in this block in a configuration file and load
# them when the script runs.
if __name__ == "__main__":
project = TFSAPI("{}".format("<server_url>"), project="<Collection/Project>", user="<user>", password="<password>", auth_type=HttpNtlmAuth)
query = project.run_query('My Queries/Last3Sprints')
With the result set in hand, the script then cycles through each of the returned work items (I’m interested in stories and bugs only) and analyzes the revision events. In my case, I’m interested when items first go into “In Progress,” when they move to “In Testing,” when they move to “Product Owner Approval,” and finally when they move to “Done.” Your status values may differ. The script is capable of displaying cycle time charts for each phase as well as the overall cycle time from when items first enter “In Progress” to when they reach “Done.” An example of overall cycle time is included at the end of this post.
When collected, I send that data to a function for creating the chart using matplotlib. I also save aside the chart data in a CSV file to help validate the chart’s accuracy based on the available data.
It’s a combination scatter plot (plt.scatter), rolling average (plt.plot), average (plt.plot), and standard deviation (plt.fill_between) of the data points. An example output (click for larger image):
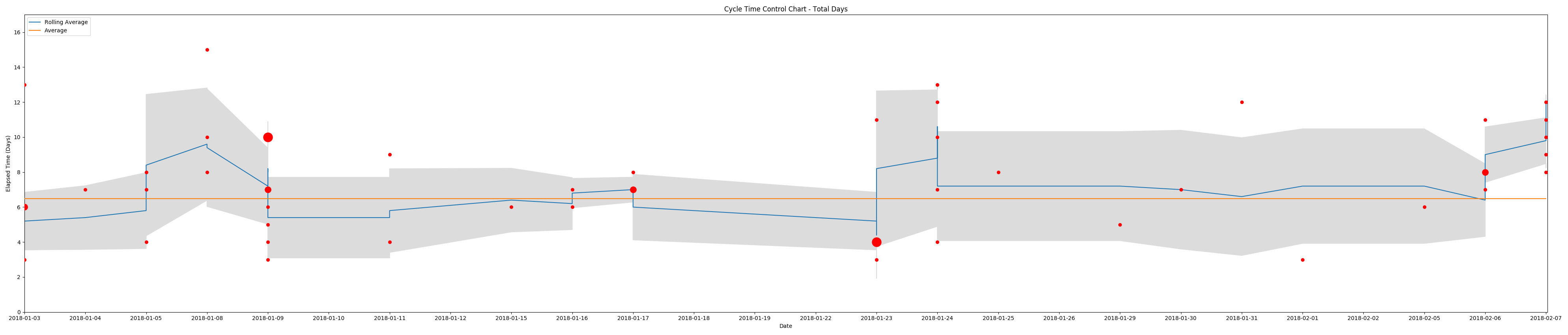
The size variation in data points reflects occurrences of multiple items moving into a status of “Done” on the same date, the shaded area is the standard deviation (sample), the blue line is the rolling average, and the orange line is the overall average.
If you are interested in learning more about how to implement this script in your organization, please contact me directly.
OnAgile 2017
Attended the Agile Alliance‘s OnAgile 2017 Conference yesterday. This is always an excellent conference and you can’t beat the price!
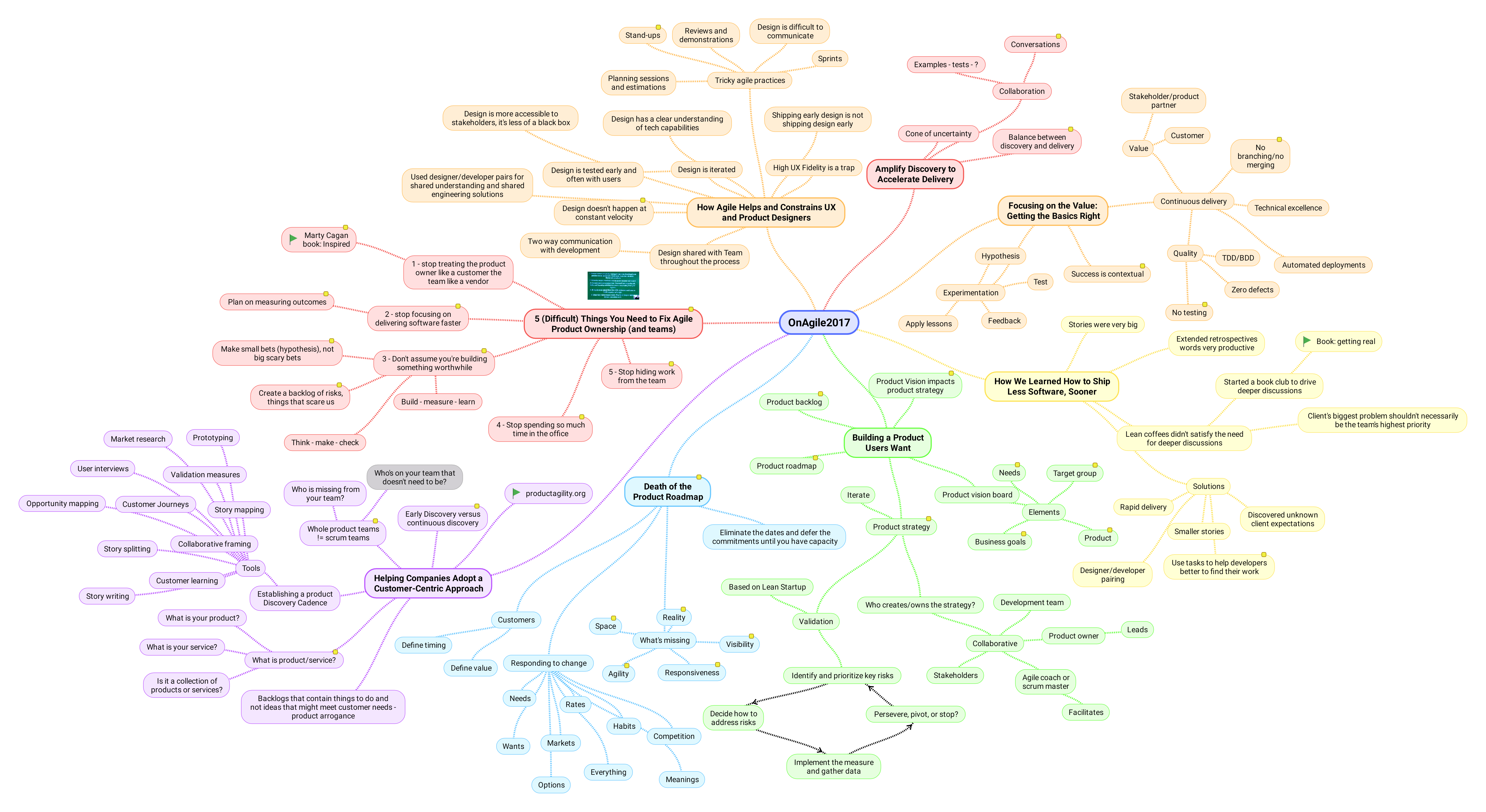
I created a mind map throughout the course of the conference as a way to organize my thoughts and key points. This doesn’t capture all the points by any means. Just those that stood out as important or new for me. I missed most of the first session due to connectivity issues.
Clouds and Windmills
I recently resigned from the company I had been employed by for over 5 years. The reason? It was time.
During my tenure1 I had the opportunity to re-define my career several times within the organization in a way that added value and kept life productive, challenging, and rewarding. Each re-definition involved a rather extensive mind mapping exercises with hundreds of nodes to described what was working, what wasn’t working, what needed fixing, and where I believed I could add the highest value.
This past spring events prompted another iteration of this process. It began with the question “What wouldn’t happen if I didn’t go to work today?”2 This is the flip of asking “What do I do at work?” The latter is a little self-serving. We all want to believe we are adding value and are earning our pay. The answer is highly filtered through biases, justifications, excuses, and rationalizations. But if in the midsts of a meeting you ask yourself, “What would be different if I were not present or otherwise not participating?”, the answer can be a little unsettling.
This time around, in addition to mind mapping skills, I was equipped with the truly inspiring work of Tanmay Vora and his sketchnote project. Buy me a beer some day and I’ll let you in on a few of my discoveries. Suffice it to say, the overall picture wasn’t good. I was getting the feeling this re-definition cycle was going to include a new employer.
A cascade of follow-on questions flowed from this iteration’s initial question. At the top:
- Why am I staying?
- Is this work aligned with my purpose?
- Have my purpose and life goals changed?
The answers:
- The paycheck
- No.
- A little.
Of course, it wasn’t this simple. The organization changed, as did I, in a myriad of ways. While exploring these questions, I was reminded of a story my Aikido teacher, Gaku Homma, would tell when describing his school. He said it was like a rope. In the beginning, it had just a few threads that joined with him to form a simple string. Not very strong. Not very obvious. But very flexible. Over time, more and more students joined his school and wove their practice into Nippon Kan’s history. Each new thread subtlety changed the character of the emerging rope. More threads, more strength, and more visibility. Eventually, an equilibrium emerges. Some of those threads stop after a few short weeks of classes, other’s (like mine) are 25 years long before they stop, and for a few their thread ends in a much more significant way.
Homma Sensi has achieved something very difficult. The threads that form Nippon Kan’s history are very strong, very obvious, and yet remain very flexible. Even so, there came a time when the right decision for me was to leave, taking with me a powerful set of skills, many good memories, and friendships. The same was true for my previous employer. Their rope is bending in a way that is misaligned with my purpose and goals. Neither good nor bad. Just different. Better to leave with many friendships intact and a strong sense of having added value to the organization during my tenure.
The world is full of opportunities. And sometimes you have to deliberately and intentionally clear all the collected clutter from your mental workspace so those opportunities have a place to land. Be attentive to moments like this before your career is remembered only as someone who yells at clouds and tilts at windmills.
1 By the numbers…
1,788 Stand-ups
1,441 Wiki/Knowledgebase Contributions
311 Sprint/Release Planning Sessions
279 Reviews
189 Retrospectives
101 Projects
31 Internal Meet-ups
22 Agile Cafés
10 Newsletters
5.5 Years
3 Distinct Job Titles
1 Wild Ride
2 My thanks to colleague Lennie Noiles and his presentation on Powerful Questions. While Lennie didn’t ask me this particular question, it was inspired by his presentation.
The Passing of a Master
 It has been several months since news of Emily Busch ‘s unexpected death and I still wrestle with the thought I shall never have the privilege of again practicing Aikido with her at Nippon Kan. The blow to Homa Sensei is undoubtedly far greater. I do not know his pain, but I am familiar with it.
It has been several months since news of Emily Busch ‘s unexpected death and I still wrestle with the thought I shall never have the privilege of again practicing Aikido with her at Nippon Kan. The blow to Homa Sensei is undoubtedly far greater. I do not know his pain, but I am familiar with it.
Looking at the growing stack of draft posts, I see about a dozen on the subject of mastery. I feel I have a lot to contribute to this subject, particularly in regard to Agile practices. And yet, I hesitate due to a sense that I still have more to learn before I’m in a position to teach on the subject. In no small measure this hesitation is counseled by having met and studied with a great many truly masterful people across a wide variety of human experience.
Emily was one of those masters.
Not only was she a master of Aikido (6th degree black belt and Sensei at Nippon Kan), she was a master jeweler. She designed and made the wedding rings for both my first and second wife along with several beautiful pendants and a set of ear rings for one of my nieces. I never had a personal jeweler before Emily and shall not have another before my time is finished on this earth.
For all her skill and mastery, she very much understood the importance of service. There was no task that needed attention at the dojo or in preparation for a seminar that was beneath her rank. And I wonder how many patrons to Domo restaurant knew they had their order taken and served by a 6th degree black belt.
Emily had already achieved the rank of black belt by the time I began practicing at Nippon Kan in 1989. My very early memories from practicing with her are of her patience and ability to skillfully instruct a 6’5″ oaf like me in the ways of Aikido – both on and off the mat. I don’t know if Emily even weighed 120 pounds, but that never stopped her from putting my sorry ass on the mat or sending me over her shoulder. Even so, I never matched Emily’s skill, even on my good days.
Those mastery related posts will have to wait a while longer. And in the wider view, my respect for those whom make claim to be masters without having done the work and earned the title have lost a little more of my respect.
Emily Sensei will be missed.
Agile Interns
I had the privilege of presenting to a group of potential interns from the Colorado School of Mines interested in agile project management. Action shot…

The slide shows what we can offer them as interns: Failure, chaos, and confusion. I unpacked that as follows…
Failure
It’s important interns have the opportunity to learn how to fail in small, deliberate and safe increments along with the opportunity to learn how to extract every possible lesson from failures and how those failures lead to eventual success. Much of our business is driven by experimentation and hypothesis testing. Most of those experiments will fail, at least initially.
Chaos
We strive to be anti-fragile. One way to accomplish this is to be good at working under chaotic and ambiguous conditions. When involved with highly evolutionary design sessions, shifting sands can seem like the most solid ground around.
Confusion
One of the values for bringing interns into the organization is the fresh perspective they offer. Why waste that on having them fetch coffee? However, interns can often be intimidated by working with people who have decades of experience under their belt. So it’s important they know they have the opportunity to work in an environment that expects questions and recognizes no one knows it all. They are in an environment that seeks alternative points of view. In this organization, everyone gets their own coffee.
Agile in the Wild
There are some decidedly Zen-like paradoxes to practicing almost any form of agile methodology. People practice agile everywhere, yet they have a hard time finding it at work. It’s the most natural form of technical project management I’ve experienced, yet people seem determined to make it harder than it is and over-think the principles. And when they shift toward simplifying their agile practice, they go contrary to good advice that everything should be made as simple as possible, but not simpler.
So a challenge: Before the month is out, take a moment to reflect on some important task you completed that had nothing to do with work and see how many things you did reflect an agile principle or common practice. Maybe it’s work you did on a hobby or at a volunteer gig. Perhaps it involved some kitchen wizardry, a tactful communication maneuver with your children, or routine house maintenance. Did you iterate across several possible solutions until you found success? Did you decide to decide something later so that you could gather more information? Did you take a particular task to “good enough” so that you could complete a more urgent related task? And which of your insights can you bring into work with you?
In this article I’ll describe a recent experience with Agile in the Wild and the lessons that can be applied in your work environment.
The challenge was how to put two 90 degree bends across a 10 inch arch in a 12 foot long, quarter inch thick piece of red oak (1) for the edge of a breakfast nook table. To do this I had to work out a way to bend long pieces of wood without having to mess with the need for a super extra-large steam box. The idea came from a shipwright named Louis Sauzedde. His trick is to use heavy poly tubing (2) to steam-bend wood in place rather than use a traditional steam box. The advantage is that the wood doesn’t cool when transferring from a steam box to a jig and, best of all for small shops, you don’t have to take up space storing a large steam box. Version 1 of my steam kettle was built using an outdoor propane burner (3), a re-purposed brew kettle (4), an oil drip pan (5), PVC piping (6), a radiator hose (7) for positioning, and the unfinished table top (8) as a jig.

#6 was a mistake. The PVC worked, but didn’t hold up to the heat. It didn’t exactly melt, but it definitely didn’t hold shape over the hour long steaming process. #8 was a big mistake. Concern about damaging the walnut top made set-up longer than it needed to be and I couldn’t get the clamps where I needed them. I was trying to take a shortcut and not hassle with making a proper jig. Oh, and another piece of important advice. Always, always, ALWAYS be wearing a good pair of work gloves (1). All parts of the steam system – burner to kettle to steam pipe to radiator hose to poly tubing to wood – are HOT and more than likely something will slip during clamping and you’ll have to grab hold. Not much fun with bare hands.

The end result was a not-quite-bent-enough piece of wood (Westie terrier, “Rose,” for scale.) The wood needed to be steamed again.

Version 1 of the steamer was modified such that the drip pan was flipped (1) for a better seal on the kettle, metal piping (2) replaced the PVC, and a more flexible radiator hose (3) was used for easier positioning. Version 2 of the steamer was a significant improvement. I got better steam output from this rig so the lignin in the wood was a little easier to bend in a shorter amount of time. Most importantly, a throw-away jig (4) was built for much better clamping.

Must have safety feature: An anti-curious-dog flame guard made out of sheep fence (1). Curious dog (2) optional.

After bending and clamping in place the steam was removed, the plastic cut away, and the wood left in the shop until I had free time to unclamp the oak from the jig. With the jig I was able to clamp the wood at multiple places across the arc. And no worries about damaging the expensive walnut of the actual table top.

Back in the shop, the edge is glued, clamped, and left to set after dealing with an unexpectedly uncooperative bend that shows signs of having been cut from stock near a knot (1).

A day to set, a lot of edge routing, and a bit of sanding shows the end result: Near-perfect 90 degree bends. I was also able to remove a little bit of twist that was occurring in the wood thanks to the better steam output from Kettle 2.0 and the use of multiple smaller clamps across the arc. The final unfinished result shows a tight fit between the edging and the table (1).

Agile Lessons
- Get help. Someone already knows the solution you seek, or most of it anyway.
- Short cuts are often the long way to get to where you are going.
- The MVP: Goes together fast, is cheap, built just good enough to actually test in the wild (safely, I would add.)
- Reuse existing assets that are adapted to suit the current need (Can equipment used for brewing beer be used in fine woodworking? Absolutely! All you have to do is think outside the brew kettle.)
- The Jig: It isn’t part of the final product. In all likelihood it won’t ever be used again. Was it waste or an essential part of getting to the final product? Design flow diagrams and wireframes are analogous to jigs. You’re supposed to throw them away! Think how utterly horrific our final products would be if we included all the interim work in what we delivered to the client.